Home
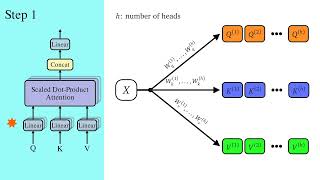
Variants of Multi-head attention: Multi-query (MQA) and Grouped-query attention (GQA)
Machine Learning Studio
Oct 29, 2023
6,446 views
Efficient Self-Attention for Transformers
Multi-Head Attention (MHA), Multi-Query Attention (MQA), Grouped Query Attention (GQA) Explained
A Dive Into Multihead Attention, Self-Attention and Cross-Attention
Learn How LLAMA 3 Works Now: The Complete Beginner’s Guide
Attention in transformers, visually explained | Chapter 6, Deep Learning
RoPE (Rotary positional embeddings) explained: The positional workhorse of modern LLMs
Attention is all you need (Transformer) - Model explanation (including math), Inference and Training
The math behind Attention: Keys, Queries, and Values matrices
Rotary Positional Embeddings: Combining Absolute and Relative
Quantization vs Pruning vs Distillation: Optimizing NNs for Inference
LLaMA explained: KV-Cache, Rotary Positional Embedding, RMS Norm, Grouped Query Attention, SwiGLU
Transformer Neural Networks, ChatGPT's foundation, Clearly Explained!!!
Self-Attention Using Scaled Dot-Product Approach
Transformer Architecture
The KV Cache: Memory Usage in Transformers
No, Einstein Didn’t Solve the Biggest Problem in Physics
But what is a GPT? Visual intro to transformers | Chapter 5, Deep Learning
What La Niña Will do to Earth in 2025
Let's build GPT: from scratch, in code, spelled out.