Home
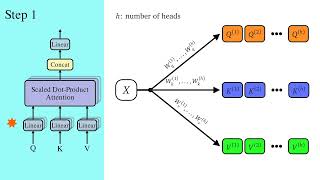
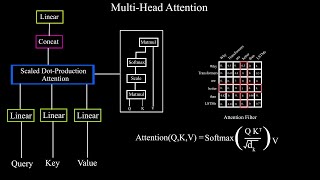
Self-Attention Using Scaled Dot-Product Approach
Machine Learning Studio
27 มี.ค. 2023
การดู 12,698 ครั้ง
A Dive Into Multihead Attention, Self-Attention and Cross-Attention
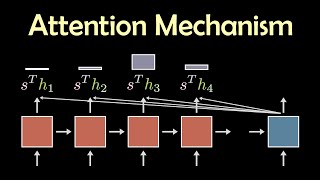
The Attention Mechanism in Large Language Models
But what is a GPT? Visual intro to transformers | Chapter 5, Deep Learning
Self-attention mechanism explained | Self-attention explained | scaled dot product attention
Transformer Attention (Attention is All You Need) Applied to Time Series
The math behind Attention: Keys, Queries, and Values matrices
How did the Attention Mechanism start an AI frenzy? | LM3
L19.4.2 Self-Attention and Scaled Dot-Product Attention
Transformer architecture | Attention is all you need شرح عربي
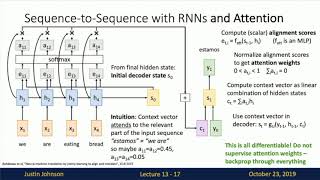
Lecture 13: Attention
Attention is all you need (Transformer) - Model explanation (including math), Inference and Training
Stanford CS25: V2 I Introduction to Transformers w/ Andrej Karpathy
Attention is all you need || Transformers Explained || Quick Explained
Pytorch Transformers from Scratch (Attention is all you need)
[딥러닝 기계 번역] Transformer: Attention Is All You Need (꼼꼼한 딥러닝 논문 리뷰와 코드 실습)
Cross Attention vs Self Attention
Longformer: The Long-Document Transformer
NLP Demystified 15: Transformers From Scratch + Pre-training and Transfer Learning With BERT/GPT
Attention Is All You Need
Self Attention vs Multi-head self Attention











![[딥러닝 기계 번역] Transformer: Attention Is All You Need (꼼꼼한 딥러닝 논문 리뷰와 코드 실습)](https://i.ytimg.com/vi/AA621UofTUA/mqdefault.jpg)




